Оптимизация PHP – главный признак профессионального кода. Как ускорить работу Apache: отдачу статических файлов и выполнение PHP? Оптимизация клиентской стороны на php
Всем доброго времени суток.
- Если метод может быть статическим, объявляйте его статическим.
- echo быстрее, чем print.
- Передавайте в echo несколько параметров, вместо того, чтобы использовать конкатенацию строк.
- Устанавливайте максимальное количество проходов ваших циклов for до цикла, а не во время его выполнения.
- Удаляйте свои переменные для освобождения памяти, тем более, если это большие массивы.
- Остерегайтесь магических методов, таких как __set, __get, __autoload.
- require_once дорого обходится.
- Указывайте полные пути в конструкциях include/require, меньше времени будет тратится на поиск файла.
- Если вам необходимо определить время, когда скрипт был запущен, используйте $_SERVER[’REQUEST_TIME’] вместо time().
- Старайтесь использовать strncasecmp, strpbrk и stripos вместо регулярных выражений.
- str_replace быстрее, чем preg_replace, но strtr быстрее, чем str_replace.
- Если функция, как и функции замены строк, может принимать в аргументы как массивы, так и одиночные символы, и если ваш список аргументов не слишком длинный, подумайте над тем, чтобы записать несколько одинаковых выражений замены, проходя один символ за раз, вместо одной строки кода, которая принимает массив как аргумент поиска и замены
- Лучше выбирать утверждения при помощи конструкции else if, чем использовать несколько конструкций if.
- Подавление ошибок при использовании @ работает очень медленно.
- Используйте модуль Apache mod_deflate.
- Закрывайте свои соединения с БД, когда закончите работать с ними.
- $row["id"] в семь раз быстрее, чем $row.
- Сообщения об ошибках дорого стоят
- Не используйте функции внутри условия цикла for, например как здесь: for ($x=0; $x < count($array); $x). В данном случае функция count() будет вызываться с каждым проходом цикла.
- Инкремент локальной переменной в методе - самый быстрый. Почти также работает инкремент локальной переменной в функции.
- Инкремент глобальной переменной в два раза медленее, чем локальной.
- Инкремент свойства объекта (т.е. $this->prop++) в три раза медленнее, чем локальной переменной.
- Инкремент неопределённой переменной в 9-10 раз медленнее, чем заранее инициализированной.
- Объявление глобальной переменной, без использования её в функции, также замедляет работу (примерно на ту же величину, что и инкремент локальной переменной). Вероятно, PHP осуществляет проверку на существование переменной.
- Скорость вызов метода, судя по всему, не зависит от количества методов, определённых в классе. Я добавил 10 методов в тестовый класс (до и после тестового метода), без изменения производительности.
- Методы в производных классах работают быстрее, чем они же, определённые в базовом классе.
- Вызов функции с одним параметром и пустым телом функции в среднем равняется 7-8 инкрементам локальной переменной ($localvar++). Вызов похожего метода, разумеется, около 15 инкрементов.
- Ваши строки, определённые при помощи ", а не ", будут интерпретироваться чуть быстрее, т.к. PHP ищет переменные внутри "..", но не "...". Конечно, вы можете использовать это только тогда, когда в вашей строке нет переменных.
- Строки, разделённые запятыми, выводятся быстрее, чем строки, разделённые точкой. Примечание: это работает только с функцией echo, которая может принимать несколько строк в качестве аргументов.
- PHP-скрипты будут обрабатываться, как минимум, в 2-10 раз медленнее, чем статические HTML-страницы. Попробуйте использовать больше статических HTML-страниц и меньше скриптов.
- Ваши PHP-скрипты перекомпилируются каждый раз, если скрипты не кэшируются. Кэширование скриптов обычно увеличивает производительность на 25-100% за счёт удаления времени на компиляцию.
- Кэшируйте, насколько это возможно. Используйте memcached — это высокопроизводительная система кэширования объектов в памяти, которая повышает скорость динамических веб-приложений за счёт облегчения загрузки БД. Кэшированный микрокод полезен тем, что позволяет вашему скрипту не компилироваться снова для каждого запроса.
- При работе со строками, когда вам понадобится убедиться в том, что строка определённой длины, вы, разумеется, захотите использовать функцию strlen(). Эта функция работает очень быстро, ведь она не выполняет каких-либо вычислений, а лишь возвращает уже известную длину строки, доступную в zval-структуре (внутренняя структура C, используемая при работе с переменными в PHP). Однако потому, что strlen() — функция, она будет работать медленно за счёт вызова некоторых операций, таких как приведение строки в нижний регистр и поиска в хэш-таблице, только после которых будут выполнены основные действия функции. В некоторых случаях вы сможете ускорить свой код за счёт использования хитрости с isset().
Было: if (strlen($foo) < 5) { echo «Foo is too short»; }
Стало: if (!isset($foo{5})) { echo «Foo is too short»; }
Вызов isset() быстрее, чем strlen() потому, что, в отличие от strlen(), isset() - не функция, а языковая конструкция. За счёт этого isset() не имеет практически никаких накладных расходов на определение длины строки. - Инкремент или декремент переменной при помощи $i++ происходит немного медленнее, чем ++$i. Это особая специфика PHP, и не нужно таким образом модифицировать свой C и Java-код думая, что он будет работать быстрее, этого не произойдёт. ++$i будет быстрее в PHP потому, что вместо четырёх команд, как в случае с $i++, вам понадобится только три. Пост-инкремент обычно используется при создании временных переменных, которые затем увеличиваются. В то время, как пре-инкремент увеличивает значение оригинальной переменной. Это один из способов оптимизации PHP-кода в байт-код утилитой Zend Optimizer. Тем не менее, это хорошая идея, поскольку не все байткод-оптимизаторы оптимизируют это, также остаётся немало скриптов, работающих без оптимизации в байткод.
- Не всё должно быть ООП, часто это излишне, поскольку каждый метод и объект занимает много памяти.
- Не определяйте каждую структуру данных как класс, массивы бывают очень полезны
- Не слишком разбивайте методы. Думайте, что вы действительно будете повторно использовать.
- Вы всегда можете разбить код на методы позже, по необходимости.
- Используйте бесчисленное количество предопределённых функций.
- Если в вашем коде есть функции, выполняющиеся очень долго, обдумайте их написание на C в виде расширения
- Профилируйте свой код. Профилирование покажет вам, как много времени выполняются части вашего кода.
- mod_gzip — модуль Apache, который позволяет сжимать ваши данные на лету и может уменьшить объем передаваемых данных до 80%.
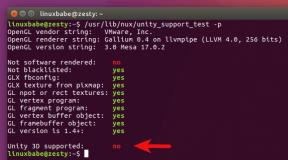
Тема данной статьи - тот факт, что применение FastCGI в PHP не ускоряет время загрузки PHP-кода по сравнению, например, с mod_php.
Большинство традиционных языков Web-программирования (Perl, Ruby, Python и т. д.) поддерживают написание скриптов, работающих в так называемом «FastCGI-режиме». Более того, Ruby on Rails, к примеру, вообще невозможно использовать в CGI-режиме, т.к. он тратит на подключение всех своих многочисленных библиотек десятки секунд.
Ниже я расскажу о методе, который позволяет в ряде случаев ускорить загрузку объемного PHP-кода более чем в 20 раз, не получая при этом побочных эффектов и значительных неудобств. Но вначале давайте поговорим об основах…
Что такое FastCGI?
Вначале поговорим, что называется, о «классическом» FastCGI, который применяют в Си, Perl, Ruby и т. д. В PHP же FastCGI имеет свои особенности, мы их рассмотрим чуть позже. Сейчас речь идет о не-PHP.
FastCGI работает следующим образом: скрипт загружается в память, запускает некоторый тяжелый код инициализации (например, подключает объемистые библиотеки), а затем входит в цикл обработки входящих HTTP-запросов. Один и тот же процесс-скрипт обрабатывает несколько различных запросов один за другим, что отличается от работы в CGI-режиме, когда на каждый запрос создается отдельный процесс, «умирающий» после окончания обработки. Обычно, обработав N запросов, FastCGI-скрипт завершается, чтобы сервер перезапустил его вновь уже в «чистой песочнице».
Для ускорения обработки стартует, конечно, не один процесс-скрипт, а сразу несколько, чтобы каждый следующий запрос не ждал обработки предыдущего. Как число одновременно запускаемых процессов, так и количество последовательных запросов на один процесс можно задавать в конфигурации сервера.
Старые скрипты, написанные с расчетом на CGI, приходится дорабатывать, чтобы они могли работать в FastCGI-окружении (касается использования FastCGI в Си, Perl и т. д.; на PHP дорабатывать не нужно, но у этого свои недостатки, см. ниже). Действительно, ведь раньше скрипт стартовал каждый раз «с чистого листа», а теперь ему приходится иметь дело с тем «мусором», который остался от предыдущего запроса. Если раньше CGI-скрипт на Perl выглядел как
use SomeHeavyLibrary; print "Hello, world!\n";
то после переделки под FastCGI он становится похож на что-то типа
use SomeHeavyLibrary; while ($request = get_fastcgi_request()) { print "Hello, world!\n"; }
Таким образом, получается экономия в скорости ответа: ведь каждый раз, когда приходит запрос, скрипту не нужно выполнять «тяжелый» код инициализации библиотек (подчас занимающий десятки секунд).
FastCGI имеет значительный недостаток: новый запрос начинает обрабатываться не в «чистом» окружении, а в том, которое осталось «с прошлого раза». Если в скрипте имеются утечки памяти, они постепенно накапливаются до тех пор, пока не произойдет крах. Это же касается и ресурсов, которые забыли освободить (открытые файлы, соединения с БД и т. д.). Есть и еще один недостаток: если код скрипта изменился, то приходится как-то сообщать об этом FastCGI-серверу, чтобы он «убил» все свои процессы и начал заново.
Собственно, техника «иницилизируйся один раз, обрабатывай много запросов» работает не только в FastCGI. Любой сервер, написанный на том же самом языке, что и скрипт, под ним запущенный, использует ее неявно. Например, сервер Mongrel написан целиком на Ruby как раз для того, чтобы под ним быстро запускать Ruby On Rails. Сервер Apache Tomcat, написанный на Java, быстро выполняет Java-сервлеты, т.к. не требует их повторной инициализации. Технология mod_perl также основана на том, что Perl-код не выгружается между запросами, а остается в памяти. Конечно, все эти серверы имеют те же самые проблемы с непредсказуемостью, утечками памяти и сложностью перезапуска, что и FastCGI-приложение.
Почему FastCGI не ускоряет PHP
Вероятно, вы слышали, что PHP тоже можно запускать в режиме FastCGI, и что так делают многие нагруженные проекты (Мамба, некоторые проекты Mail.Ru и т. д.). Это якобы дает «существенный прирост» производительности, потому что (согласно слухам) FastCGI экономит время инициализации скрипта и подключения библиотек.
Не верьте! В действительности поддержка FastCGI в PHP имеет чисто номинальный характер. Точнее, она не дает преимуществ в том смысле, в котором ей привыкли оперировать для уменьшения времени инициализации скрипта. Конечно, вы можете запустить PHP FastCGI-сервер и даже заставить nginx или lighttpd работать с ним напрямую, однако прирост скорости на загрузку кода, который вы от этого получите, будет нулевым. Тяжелые PHP-библиотеки (например, Zend Framework) как загружались долго в mod_php- или CGI-режимах, так и будут продолжать загружаться долго в режиме FastCGI.
Собственно, это неудивительно: ведь чтобы запустить любой PHP-скрипт в FastCGI-режиме, его не приходится дорабатывать. Ни строчки измененного кода! Когда я впервые решил поэкспериментировать с FastCGI в PHP, я потратил несколько часов времени на поиски в Интернете информации о том, как именно следует модифицировать PHP-код, чтобы оптимально запускать его в режиме FastCGI. Я проштудировал всю документацию PHP и несколько десятков форумов PHP-разработчиков, даже просмотрел исходный код PHP, но так и не нашел ни единой рекомендации. Имея прежний опыт работы с FastCGI в Perl и Си, я был несказанно удивлен. Однако все встало на свои места, когда выяснилось, что изменять код не нужно и, хотя в рамках одного FastCGI-процесса обрабатываются несколько соединений, PHP-интерпретатор каждый раз инициализируется заново (в отличие от «классического» FastCGI). Более того, похоже, большинство PHP-разработчиков, радостно использующих FastCGI+PHP, даже не подозревают о том, что оно должно работать как-то по-другому…
eAccelerator: ускорение повторной загрузки PHP-кода
Каждый раз, когда PHP-скрипт получает управление, PHP компилирует (точнее, транслирует) код скрипта во внутреннее представление (байт-код). Если файл небольшой, трансляция происходит очень быстро (Zend Engine в PHP - один из лидеров по скорости трансляции), однако, если включаемые библиотеки «весят» несколько мегабайтов, трансляция затягивается.
Существует ряд инструментов, кэширующих в разделяемой оперативной памяти (shared memory) оттранслированное внутреннее представление PHP-кода. Таким образом, при повторном включении PHP-файла он уже не транслируется, а байт-код берется из кэша в памяти. Естественно, это значительно ускоряет работу.
Одним из таких инструментов является eAccelerator. Он устанавливается в виде расширения PHP (подключается в php.ini) и требует самой минимальной настройки. Рекомендую включить в нем режим кэширования байт-кода исключительно в оперативной памяти и отключить сжатие (установить параметры eaccelerator.shm_only=1 и eaccelerator.compress=0). Также установите и настройте контрольную панель control.php, идущую в дистрибутиве eAccelerator, чтобы в реальном времени отслеживать состояние кэша. Без контрольной панели вам будет очень трудно проводить диагностику, если eAccelerator по каким-то причинам не заработает.
Преимущество eAccelerator в том, что он работает весьма стабильно и быстро даже на больших объемах PHP-кода. У меня ни разу не возникало проблем с этим инструментом (в отличие от Zend Accelerator, к примеру).
«Мой скрипт вместе с библиотеками занимает 5 МБ, как же быть?..»
Думаете, 5 МБ кода - это чересчур много для PHP? Ничего подобного. Попробуйте воспользоваться такими системами, как Zend Framework и Propel , чтобы убедиться в обратном. Zend Framework целиком занимает как раз около 5 МБ. Классы, сгенерированные Propel-ом, также весьма объемисты и могут отнять еще несколько мегабайтов.
Многие на этом месте посмеются и скажут, что не надо использовать Zend Framework и Propel, т.к. они «тормозные». Но действительность заключается в том, что тормозные вовсе даже не они… Плохую производительность имеет метод, который по умолчанию использует PHP для загрузки кода. К счастью, ситуацию нетрудно исправить.
Чтобы не быть голословным, я приведу результаты небольшого тестирования, которое я специально провел в «чистом» окружении, не привязанном к какому-либо конкретному проекту. Тестировалась скорость подключения всех файлов Zend Framework (за исключением Zend_Search_Lucene). Предварительно из кода были вырезаны все вызовы require_once, а загрузка зависимостей поизводилась только через механизм autoload .
Итак, всего подключались 790 PHP-файлов общим объемом 4.9 МБ. Немало, верно? Подключение осуществлялось примерно так:
function __autoload($className) { $fname = str_replace("_", "/", $className) . ".php"; $result = require_once($fname); return $result; } // Подключаем классы один за другим в порядке их зависимостей. class_exists("Zend_Acl_Assert_Interface"); class_exists("Zend_Acl_Exception"); class_exists("Zend_Acl_Resource_Interface"); class_exists("Zend_Acl_Resource"); // ... и так для всех 790 файлов
Благодаря тому, что используется autoload, вызов class_exists() заставляет PHP подключить файл соответствующего класса. (Это самый простой способ «дернуть» autoload-функцию.) Порядок подключения я выбрал таким, чтобы каждый следующий класс уже имел загруженными все свои зависимые классы на момент запуска. (Этот порядок нетрудно установить, просто печатая в браузер значение $fname в функции __autoload).
Вот результаты тестирования с eAccelerator-ом и без на моем не очень мощном ноутбуке (Apache, mod_php):
- Подключение всех файлов по одному, eAccelerator выключен: 911 мс.
- Подключение всех файлов по одному, eAccelerator включен: 435 мс. Занято 15 М кэш-памяти под байт-код.
Как видите, eAccelerator дает примерно двукратное ускорение на 790 файлах общим объемом 4.9 МБ. Слабовато. К тому же, 435 мс - явно чересчур для скрипта, который только и делает, что подключает библиотеки.
А теперь добавим стероидов
Ходят слухи, что PHP гораздо быстрее загружает один большой файл, чем десять маленьких того же суммарного объема. Я решил проверить это утверждение, объединив весь Zend Framework в один файл размером 4.9 МБ и подключив его единственным вызовом require_once. Давайте посмотрим, что получилось.
- Включение одного большого слитого файла, eAccelerator выключен: 458 мс.
- Включение одного большого слитого файла, eAccelerator включен: 42 мс. Занято 31 МБ кэш-памяти под байт-код.
Первая строчка говорит о том, что один большой файл размером 4.9 МБ и правда загружается быстрее, чем 790 маленьких: 458 мс против 911 мс (см. выше). Экономия в 2 раза.
А вот вторая строчка заставила меня от удивления подпрыгнуть на стуле и перепроверить результат несколько раз. Надеюсь, это же произойдет и с вами. Действительно, 42 мс - это в 11 раз быстрее, чем с отключенным eAccelerator-ом! Получается, что eAccelerator еще меньше любит мелкие файлы (кстати, даже в режиме eaccelerator.check_mtime=0): экономия в 11 раз.
Итак, мы действительно получили ускорение загрузки в 22 раза, как и было обещано в заголовке. Раньше весь Zend Framework, разбитый на файлы, подключался 911 мс, а с использованием eAccelerator и объединенем всех файлов в один - 42 мс. И это, заметьте, не на реальном сервере, а всего лишь на рядовом ноутбуке.
Вывод: ускорение в 22 раза
Подведем итоги.
- Слияние всех файлов в один большой плюс включение eAccelerator для этого большого файла дает ускорение в 22 раза при объеме кода 4.9 МБ и числе файлов 790.
- В случае небольшого числа файлов значительного объема eAccelerator может дать 10-кратное ускорение. Если файлов много, а суммарный объем большой, то ускорение примерно в 2 раза.
- Расход кэш-памяти зависит от числа файлов разбиения: при фиксированном объеме чем файлов больше, тем расход меньше.
При всем при этом eAccelerator лишен основных проблем «настоящего» FastCGI-сервера. Скрипты избавлены от утечек памяти и запускаются в гарантировано «чистом» окружении. Вам также не надо следить за изменением кода и перезапускать сервер всякий раз, когда внесены модификации в мало-мальски глубинный код системы.
Заметьте также, что мы подключали весь Zend Framework. В реальных скриптах объем кода будет сильно меньше, т.к. обычно для работы требуется лишь незначительная часть ZF. Но даже при условии, что библиотеки занимают 4.9 МБ, мы получаем время загрузки 42 мс - вполне приемлемое для PHP-скрипта. Ведь в нагруженных проектах PHP-скрипты могут работать и несколько сотен миллисекунд (Facebook, Мой Круг и т. д.).
Конечно, если вы планируете запускать FastCGI в PHP не из соображений производительности, а просто чтобы не «завязываться» за Apache и ограничиться связкой «nginx+PHP» или «lighttpd+PHP», ничто этому не мешает. Более того, задействовав eAccelerator для FastCGI+PHP и слив много файлов кода в один большой, вы получите то же самое ускорение, которое я описал выше. Однако не тешьте себя надеждами, что ускорение дал именно FastCGI: это не так. Применяя mod_php+eAccelerator, вы достигли бы практически такого же результата, что и FastCGI+eAccelerator.
Вручную объединять все файлы библиотек в один - утомительное занятие. Лучше написать утилиту, которая будет автоматически анализировать список PHP-файлов, подключенных скриптом, а при следующем запуске - объединять эти файлы и записывать во временную директорию (если это еще не сделано), после чего - подключать по require_once. Сегодня я оставляю написание такой утилиты (плюс-минус детали) на совести читателя.
Также рекомендую вам отказаться от явного включения файлов по require_once и переходить на autoload. Только не пытайтесь использовать для этого Zend_Loader: он очень медленный (по моим замерам, подключение ста файлов отнимет дополнительно около 50 мс). Лучше напишите собственную несложную autoload-функцию, которая будет быстро выполнять всю работу. Autoload позволит вам безопасно объединять несколько файлов библиотек в один, не думая о том, как бороться с «ручными» require_once.
Наконец, применяйте функцию set_include_path() , чтобы код подключения библиотек выглядел вот так:
require_once "Some/Library.php";
require_once LIB_DIR . "/Some/Library.php";
Константы, определяющие путь к директории библиотек явным образом, - большое зло и усложнение программы. Они также косвенно противоречат стандартам кодирования Zend Framework и PEAR, которых я тоже рекомендую по возможности придерживаться.
Итак, хотите использовать «тяжелые» библиотеки в PHP-скриптах - на здоровье! PHP - скриптовый язык, по-настоящему позволяющий это делать без оглядки на неудобства FastCGI и проблемы «встроенных» серверов.
Одним из основных критериев успешности любого интернет-ресурса является скорость его работы и с каждым годом пользователи становятся всё более и более требовательными по этому критерию. Оптимизация работы php-скиптов - это один из методов обеспечения скорости работы системы.
В этой статье я бы хотел представить на суд общественности свой сборник советов и фактов по оптимизации скриптов. Сборник собирался мною достаточно долго, основан на нескольких источниках и личных экспериментах.
Почему сборник советов и фактов, а не жестких правил? Потому что, как я убедился, не существует «абсолютно правильной оптимизации». Многие приёмы и правила противоречивы и выполнить их все невозможно. Приходиться выбирать совокупность методов, которыми приемлемо пользоваться без ущерба безопасности и удобности. Я занял рекомендательную позицию и поэтому у меня советы и факты, которые Вы можете соблюдать, а можете и не соблюдать.
Что бы не было путаницы, я разделил все советы и факты на 3 группы:
- Оптимизация на уровне логики и организации приложения
- Оптимизация кода
- Бесполезная оптимизация
Группы выделены условно и некоторые пункты можно отнести сразу к нескольким из них. Цифры приведены для среднестатистического сервера (LAMP). В статье не рассматриваются вопросы связанные с эффективностью различных сторонних технологий и фреймворков, так как это тема отдельных дискуссий.
Оптимизация на уровне логики и организации приложения
Многие из советов и фактов, относящихся к данной группе оптимизации, являются весьма значимыми и дают весьма большой выигрыш во времени.
- Постоянно профилируйте свой код на сервере (xdebug) и на клиенте (firebug), что бы выявить узкие места кода
Следует отметить, что профилировать надо и серверную, и клиентскую часть, так как не все серверные ошибки можно обнаружить на самом сервере. - Количество, используемых в программе пользовательских функций, никак не влияет на скорость
Это позволяет использовать в программе бесчисленное число пользовательских функций. - Активно используйте пользовательские функций
Положительный эффект достигается за счёт того, что внутри функций операции ведутся только с локальными переменными. Эффект этого больше, чем расходы на вызовы пользовательских функций. - «Критически тяжёлые» функции желательно реализовать на стороннем языка программирования в виде расширения PHP
Это требует навыков программирования на стороннем языке, что значительно увеличивает время разработки, но в тоже время позволяет использовать приёмы вне возможности PHP. - Обработка статического файла html быстрее, чем интерпретируемого файла php
Различие повремени на клиенте может составлять около 1 секунды, поэтому имеет смысл четкое разделение статики и генерируемых средствами PHP страниц. - Размер обрабатываемого (подключаемого) файла влияет на скорость
Примерно на обработку каждых 2 Кб тратиться 0.001 секунды. Этот факт толкает нас на проведение минимизации кода скриптов при перенесении на рабочий сервер. - Старайтесь не использовать постоянно require_once или include_once
Эти функции нужно использовать при наличии возможности повторного считывания файла, в остальных случаях желательно использовать require и include . - При ветвлении алгоритма, если имеются конструкции, которые могут не обрабатываться и их объём порядка 4 Кб и более, то более оптимально их подключать при помощи include.
- Желательно использовать проверку отправляемых данных на клиенте
Это вызвано тем, что при проверке данных на стороне клиента, резко снижается количество запросов с неверными данными. Системы проверки данных на клиенте строятся в основном с использованием JS и жестких элементов формы (select). - Желательно большие конструкций DOM для массивов данных строить на клиенте
Это очень эффективный метод оптимизации при работе с отображением большого объёма данных. Суть его сводится к следующему: на сервере подготавливается массив данных и передаётся клиенту, а построение конструкций DOM предоставляется JS функциям. В результате нагрузка частично перераспределяется с сервера на клиент. - Системы, построенные на технологии AJAX, значительно быстрее, чем системы, не использующие эту технологию
Это вызвано уменьшением объёмов вывода и перераспределением нагрузки на клиента. На практике скорость систем с AJAX в 2-3 раза выше. Замечание: AJAX в свою очередь создаёт ряд ограничений на использование других методов оптимизации, например, работа с буфером. - При получение post-запроса всегда возвращайте что-нибудь, можно даже пробел
Иначе клиенту будет отправлена страница ошибки, которая весит несколько килобайт. Данная ошибка очень часто встречается в системах, использующих технологию AJAX. - Получение данных из файла быстрее, чем из БД
Это во многом вызвано затратами на подключение к БД. К моему удивлению, огромный процент программистов маниакально хранят все данные в БД, даже когда использование файлов быстрее и удобнее. Замечание: в файлах можно хранить данные, по которым не ведётся поиск, в противном случае следует использовать БД. - Не осуществляйте подключение к БД без необходимости
По неизвестной мне причине, многие программисты осуществляют подключение к БД на этапе считывания настроек, хотя далее они могут не делать запросов к БД. Это вредная привычка, которая стоит в среднем 0.002 секунды. - Используйте постоянное соединение с БД при малом количестве одновременно активных клиентов
Выгода во времени вызвана отсутствием затрат на подключение к БД. Разница во времени примерно 0.002 секунды. Замечание: при большом количестве пользователей постоянные соединения использовать нежелательно. При работе с постоянными соединениями должен быть механизм завершения соединений. - Использование сложных запросов к БД быстрее, чем использование нескольких простых
Разница во времени зависит от многих факторов (объём данных, настройка БД и пр.) и измеряется тысячными, а иногда даже сотыми, секунды. - Использование вычислений на стороне СУБД быстрее, чем вычисления на стороне PHP для данных хранящихся в БД
Это вызвано тем фактором, что для таких вычислений на стороне PHP требуется два запроса к БД (получение и изменение данных). Разница во времени зависит от многих факторов (объём данных, настройка БД и пр.) и измеряется тысячными и сотыми секунды. - Если данные выборки из БД редко меняются и к этим данным обращается множество пользователей, то имеет смысл сохранить данные выборки в файл
Например можно использовать следующий простой подход: получаем данные выборки из БД и сохраняем их как сериализованный массив в файл, далее любой пользователь использует данные из файла. На практике такой метод оптимизации может дать многократный прирост скорости выполнения скрипта. Замечание: При использовании данного метода требуются писать инструменты для формирования и изменения данных хранимых файле. - Кэшируйте данные, которые редко меняются, при помощи memcached
Выигрыш времени может быть весьма значительным. Замечание: кэширование эффективно для статичных данных, для динамичных данных эффект снижается и может быть отрицательным. - Работа без объектов (без ООП) быстрее, чем работа с использованием объектов, примерно, в три раза
Памяти «съедается» также больше. К сожалению, интерпретатор PHP не может работать с ООП также быстро как с обычными функциями. - Чем больше мерность массивов, тем медленнее они работают
Потеря времени возникает из-за обработки вложенности структур.
Оптимизация кода
Данные советы и факты дают незначительны по сравнению с предыдущей группой прирост скорости, но в своей совокупности эти приёмы могут дать неплохой выигрыш времени.
- echo и print значительно быстрее, чем printf
Разница во времени может доходить до нескольких тысячных секунды. Это вызвано тем, что printf служит для вывода форматированных данных и интерпретатор проверяет полностью строку на вхождение таких данных. printf используется только для вывода данных, которым нужно форматирование. - echo $var."text" быстрее, чем echo "$var text"
Это вызвано тем, что движок PHP во втором случае вынужден искать переменные внутри строки. Для больших объёмов данных и старых версий PHP различия по времени заметны. - echo "a" быстрее, чем echo "a" для строк без переменных
Это вызвано тем, что во втором случае движок PHP пытается найти переменные. Для больших объёмов данных различия во времени достаточно заметны. - echo "a","b" быстрее, чем echo "a"."b"
Вывод данных через запятую быстрее, чем через точку. Это вызвано тем, что во втором случае происходит конкатенация строк. Для больших объёмов данных различия во времени достаточно заметны. Примечание: это работает только с функцией echo, которая может принимать несколько строк в качестве аргументов. - $return="a"; $return.="b"; echo $return; быстрее, чем echo "a"; echo "b";
Причина в том, что вывод данных требует некоторых дополнительных операций. Для больших объёмов данных различия во времени достаточно заметны. - ob_start(); echo "a"; echo "b"; ob_end_flush(); быстрее, чем $return="a"; $return.="b"; echo $return;
Это вызвано тем, что вся работа осуществляется без обращения к переменным. Для больших объёмов данных различия во времени достаточно заметны. Замечание: данный прием неэффективен, если вы работаете с AJAX, так как в этом случае данные желательно возвращать в виде одной строки. - Используйте «профессиональную вставку» или?> a b
Статические данные (вне программного кода) обрабатываются быстрее, чем вывод данных PHP. Этот прием называется профессиональной вставкой. Для больших объёмов данных различия во времени достаточно заметны. - readfile быстрее, чем file_get_contents , file_get_contents быстрее, чем require , а require быстрее, чем include для вывода статического контента из отдельного файла
По времени считывания пустого файла колебания от 0.001 для readfile до 0.002 для include . - require быстрее, чем include для интерпретируемых файлов
Замечание: при ветвлении алгоритма, когда есть возможность не использовать интерпретируемый файл, надо использовать include , т.к. require подключает файл всегда. - if (...) {...} else if (...) {} быстрее, чем switch
Время зависит от количества веток. - if (...) {...} else if (...) {} быстрее, чем if (...) {...}; if (...) {};
Время зависит от количества веток и условий. Необходимо использовать else if везде, где это возможно, так как это самая быстрая «условная» конструкция. - Наиболее часто встречающиеся условия конструкции if (...) {...} else if (...) {} надо помещать в начале ветвления
Интерпритатор просматривает конструкцию сверху вниз, пока не найдет выполнение условия. Если интерпретатор находит выполнение условия, то остальныю часть конструкции он не просматривает. - < x; ++$i) {...} быстрее, чем for($i = 0; $i < sizeOf($array); ++$i) {...}
Это вызвано тем, что во втором случае операция sizeOf будет выполнятся при каждой итерации. Время разницы выполнения зависит от числа элементов массива. - x = sizeOf($array); for($i = 0; $i < x; ++$i) {...} быстрее, чем foreach($arr as $value) {...} для не ассоциативных массивов
Разница во времени значительна и увеличивается при увеличении массива. - preg _replace быстрее, чем ereg_replace , str_replace быстрее, чем preg_replace , но strtr быстрее, чем str_replace
Разница во времени зависит от объёма данных и может достигать нескольких тысячных секунд. - Функции работы со строками быстрее, чем регулярные выражения
Это правило является следствием предыдущего. - Удаляйте уже ненужные переменные-массивы для освобождения памяти.
- Старайтесь не использовать подавление ошибок @
Подавление ошибок производит ряд очень медленных операций, а так как частота повтора может быть очень большой, потери скорости могут быть значительными. - if (isset($str{5})) {...} быстрее, чем if (strlen($str)>4){...}
Это вызвано тем, что вместо функции для работы со строками strlen используется стандартная операция проверки isset . - 0.5 быстрее, чем 1/2
Причина в том, что во втором случае выполняется операция деления. - return быстрее, чем global при возвращении значения переменной из функции
Это вызвано тем, что во втором случае создаётся глобальная переменная. - $row["id"] быстрее, чем $row
Первый вариант быстрее в 7 раз. - $_SERVER[’REQUEST_TIME’] быстрее, чем time() для определения времени запуска скрипта
- if ($var===null) {...} быстрее, чем if (is_null($var)) {...}
Причина в том, что в первом случае нет использования функции. - ++i быстрее, чем i++ , --i быстрее, чем i--
Это вызвано особенностями ядра PHP. Разница по времени менее 0.000001, но если у Вас данные процедуры повторяются тысячи раз, то присмотритесь к данной оптимизации. - Инкремент инициализированной переменой i=0; ++i; быстрее, чем не инициализированной ++i
Разница по времени около 0.000001 секунды, но из-за возможной частоты повтора следует помнить данный факт. - Использование «отработавших» переменных быстрее, чем объявление новых
Или перефразирую иначе – Не создавайте лишних переменных. - Работа с локальными переменными быстрее, чем с глобальными, примерно, в 2 раза
Хоть и разница во времени менее 0.000001 секунды, но из-за высокой частоты повторения следует стараться работать с локальными переменными. - Обращение к переменной напрямую быстрее, чем вызов функции, внутри которой определяется эта переменная в несколько раз
На вызов функции тратиться примерно в три раза больше времени, чем на вызов переменной.
Бесполезная оптимизация
Ряд методов оптимизации на практике не оказывают большого влияния на скорость выполнения скриптов (выигрыш времени менее 0.000001 секунды). Несмотря на это, такая оптимизация зачастую становиться предметом споров. Я привел данные «бесполезные» факты для того, чтобы вы в последующим не уделяли им особого внимания при написании кода.
- echo быстрее, чем print
- include("абсолютный путь") быстрее, чем include("относительный путь")
- sizeOf быстрее, чем count
- foreach ($arr as $key => $value) {...} быстрее, чем reset ($arr); while (list($key, $value) = each ($arr)) {...} для ассоциативных массивов
- Не комментированный код быстрее, чем комментированный, так как уходит дополнительное время на чтение файла
Весьма глупо уменьшать объём комментариев ради оптимизации, надо просто в рабочих («боевых») скриптах проводить минимизацию. - Переменные с короткими названиями быстрее, чем переменные с длинными названиями
Это вызвано сокращением объёмов обрабатываемого кода. Аналогично предыдущему пункту, надо просто в рабочих («боевых») скриптах проводить минимизацию. - Разметка кода с использованием табуляции быстрее, чем с использованием пробелов
Аналогично предыдущему пункту.
Напоследок, хочу раз напомнить, что приведённые мною советы и факты не абсолютны и значимость их применения зависит от конкретной ситуации. Необходимо помнить, что оптимизация скриптов лишь малая часть от всей процедуры оптимизации и зачастую возможно спокойно жить без вышеописанных советов.
Если у Вас возникли вопросы, то для скорейшего получения ответа рекомендуем воспользоваться нашим
Как без особых усилий заставить PHP -код работать на порядок быстрее ? Перед тем как задаваться вопросами кеширования и масштабирования стоит попробовать оптимизировать код. Есть ряд несложных правил:
Еще про оптимизацию....
При вставке кусков PHP-кода в HTML страницы всегда используйте полные открывающие и закрывающие скобки ! Это обезопасит Вас от вариаций настройки php.ini short_open_tag на разных серверах и возможно сэкономит много времени при переносе или загрузке проектов на разные сервера.
Старайтесь использовать функцию вывода echo вместо printf и sprintf там где возможно. Нет надобности использовать эти функции, так как они выполняются медленней потому, что созданы для интерпретации и вывода строки с ее обработкой, подстановкой значений, в отформатированном виде. О чем и говорит буква f в конце названия этих 2-х функций.
Sprintf("мама"); printf("папа");
Echo "мама"; echo "папа";
По тем же причинам используйте одинарные кавычки там где это возможно и пользуйтесь оператором "." для склейки строк, вместо прямой подстановки переменный в строку, заключенную в кавычки.
Лучший вариант(самый быстрый)
Echo "Вес равен: ".$weight;
Худший вариант(медленный):
Echo "Вес равен: $weight";
Если Вам нужно проверить не равно ли возвращенное значение функции нулю (а функция сама по себе возвращает только положительные или только отрицательные значения), то лучше использовать оператор сравнения. Он выполняется быстрей, нежели конкретное сравнение значений.
$i = 0; if ($i != 0) { //Не равно } else { //Равно }
$i = 0; if ($i > 0) { //Не равно } else { //Равно } Нужно также учитывать, что если строка принимает только пустое значения, либо пользовательские строковые данные, то вместо сравнения строки со строкой, для выявления ее пустоты, так же можно использовать сравнение с нулем, которые выполнится быстрее.
Для проверки строки на пустоту используйте функцию trim($str) ; Она не только проверит заполнена ли строка, но также обрежет несущественные символы - пробелы (табуляции, white-spaces) и вернет положительное значение, в случае если в строке ей действительно какие то значимые символы.
If ($str != "") { //обработка строки }
If (trim($str)) { //обработка строки }
Для получения данных из форм методом Get и Post лучше использовать следующий минимальный набор самописных функций:
GetParam ($array, $value, $default = "") { return (isset($array[$value])) ? $array[$value] : $default; } GetParamSafe ($array, $value, $default = "") { return (isset($array[$value])) ? addslashes($array[$value]) : $default; }
Функция GetParam($_POST, "myvar", "empty") к примеру коректно получит данные из $_POST["myvar"], и в случае если $_POST переменная не существует вернет значение по умолчанию, без всяких Waring и Notice. Фунция GetParamSafe($_POST, "myvar", "empty") делает ту же операцию, только возвращает экранированную переменную. Для защиты от SQL инъекций к примеру. А данная конструкция позволяет получить целочисленное число из $_POST.
Intval(GetParam($_POST, "myvar", "empty")):
В случае если в массиве $_POST лежало совсем не число функия вернет 0;
Для простого сравнения строк не используйте preg_match() или preg_match_all() . Используйте strstr() и strpos() .
При получении строк из базы данных (MySQL к примеру) старайтесь использовать функцию mysql_fetch_object . К примеру при изменении кода запроса с
$query = "SELECT field7, field3 FROM mytable WHERE id = 5" на $query = "SELECT * FROM mytable WHERE id = 5" код вывода строки полученной из этих запросов $row = mysql_fetch_array(mysql_query($query)); echo $row."-->".$row; //перестанет работать, в то время, как $row = mysql_fetch_object(mysql_query($query)); echo $row->field7."-->".$row->field3; // останется работоспособным.
При использовании сессий для авторизации на сайте, храните в сессии хотя бы IP-адрес, с которого был совершен вход. Так же проверяйте IP входа с текущим IP адресом каждый раз при выполнении закрытого скрипта. Например если злоумышленнику удастся украсть название сессии, то войти он в закрытую часть уже не сможет. Потому что в общем случае у него будет другой IP-адрес.
При формировании больших запросов вставки данных в БД через insert все строчки старайтесь поместить в один-три insert"а. Выполнение каждой строчки отдельно не только загрузит сервер БД, но и задержит работу Вашего скрипта.
В случае если необходимо в разных местах (разных классах) одной системы использовать одни и те же сложно вычисляемые данные (например которые достаются из БД через запрос с последющей обработкой строк), старайтесь их вычислять единожды, хранить глобально для всей системы и передавать в класс(скрипт) один раз, непосредственно при создании класса (подключении скрипта)
При больших нагрузках на Web-сервер задумайтесь над использованием стандартных решений для включения кэша(кэш-технологии). Например бесплатный PHP класс JCache_Lite_Function.
При проектировании/разработке больших систем отдавайте предпочтение Объектно-Ориентированному программированию с использование шаблонов проектирования. Наиболее частые шаблоны: MVC, PageController, BodyHandler, Fabric...
Читать дальше:
Производительность решений на PHP — частая тема различных споров и дискуссий. Мы не будем сейчас участвовать в них. Ведь как бы там ни было, все всегда зависит от конкретной задачи. К примеру, мне известен достоверный случай, когда некий программный код в течение полутора года переписывали на Ассемблере. Изначально он был написан на Си. Когда работы завершились, позади остались сотни рабочих дней большой группы разработчиков, а на руках — версия ПО, полностью написанная на Ассемблере. Какое же было удивление команды, когда в итоге их творение на Ассемблере заработало гораздо медленней их же, более раннего творения на Си!
Оптимизация программного кода — задача многогранная. Следует учитывать множество факторов. Следует понимать, что в ряде случаев ею вообще можно пренебречь: в конце концов, часто проще докупить высокопроизводительного «железа», чем оплачивать дополнительную работу команды высококлассных разработчиков. Автоматизация, индустриализация, други мои! Роботы заменяют людей. А ведь когда-то были такие профессии, как, например, профессия фонарщика или лифтера, нет, не того, который сейчас чинит и обслуживает лифты. Того, который раньше был штурманом лифта и возил пассажиров куда они просили. Сейчас это уже кажется смешным. А лет через энное количество смех будут вызывать пилоты самолетов. Те будут летать на полностью автоматизированных системах управления И т.д.
Так или иначе, нет смысла оптимизировать очень простые, либо редко используемые части программного обеспечения. По крайней мере до того момента, пока все остальное не в полном порядке. А на что именно следует обратить внимание в первую очередь? Сейчас мы об этом и будем говорить.
Рассмотрим на примере PHP. На самом деле, что бы там не говорили о нем, PHP ничуть не хуже Perl или ASP.NET, я бы сказал даже наоборот — у PHP значительно больше преимуществ. Почему же ему чаще всех достается? Очень просто — потому, что он самый популярный! Ведь и Windows ругают все, под нее больше всего вирусов, в ней больше всего найденных «дыр». Но стоит на ее популярность… Хм более 98% пользователей работают именно под ОС Windows. На все остальные вместе взятые операционные системы приходится не более 2% пользователей. Не удивительно, что к Windows такое внимание. Я уверен, что если любая другая ОС была бы настолько же популярна (и настолько же сложна, функциональна и доступна), в ней было бы найдено не меньше дыр. Ну да ладно, это разговор для отдельной темы.
Возвращаясь к PHP, кроме всего прочего, это, пожалуй, наиболее простой язык программирования, широко применяемый для веба. Его простота и доступность обусловливают возникшую армию новичков, которые хоть что-то в нем пытаются делать. Их некомпетентность часто становится причиной негативных дискуссий о PHP. Тот же ASP.NET не столь доступен. Как следствие — основные его «носители» — достаточно грамотные люди. Со всеми вытекающими последствиями. Но ведь доступность PHP никоим образом не нивелирует его достоинств в руках профессионалов.
В конце концов, на чем написана самая популярная социальная сеть, и второй по посещаемости веб-ресурс в мире, facebook? А его аналог vkontakte? Конечно же, на PHP!
Следует понимать область применения. Если вам нужно проводить серьезные вычисления, особенно связанные с мультимедиа, с большими данными и высокими нагрузками, например, обработкой видео онлайн, конечно же, лучше написать соответствующий код на том же Си и уже использовать его под PHP как откомпилированный модуль. PHP — это скорее некий универсальный шаблонизатор, чем язык программирования, каким мы его понимаем. У PHP задачи совсем иные.
В связи с этим, в оптимизации производительности PHP кода и подходы иные: тут важней оптимизация самого алгоритма, модели решения задачи, чем конкретно кода. Хотя есть и исключения.
7 принципов, или 7 позиций оптимизации кода PHP.
1) Любовь к готовым библиотекам.
Различные готовые библиотеки — вещи, безусловно, полезные и удобные. Но следует не забывать, что бесплатный сыр бывает только в мышеловке. За все, так или иначе, а платить приходится.
Разработка программного обеспечения для реализации задумки некоего сайта всегда (при условии соотносимых уровней исполнителей, конечно же) в плане производительности будет значительно более выгодна, чем применение готовой, универсальной CMS (Content Management System — система управления содержимым, «движок» сайта). Низкая производительность — расплата за универсальность CMS. Это то — же самое, что ездить на базар на личном автобусе, или даже, на самолете, но не на своем легковом автомобиле. То же самое и с готовыми библиотеками.
Но почему я поставил библиотеки на первое место? Потому, что если они применяются, то сразу съедают львиную долю производительности. Смотрите сами: подключение одних только Smarty и DbSimple сразу же «съедает» порядка 0.025 сек. времени и почти 3/4 Мб ОЗУ. И это на неплохом сервере при низкой общей нагрузке. Добавить сюда еще какой-нибудь phpMailer , и мы имеем 0.03 сек. затраченного времени и 1 Мб сожранной памяти попросту на пустом месте. Мы еще ничего не делали, лишь подключили модули, это еще даже без их инициализации! У меня есть один самописный проект, наподобие социальной сети, так в нем на полное создание странички в среднем уходит ощутимо меньше ресурсов. Другой пример — движок новостного сайта, который я разрабатывал: публикации, комментарии и т.д. По большому счету, ничего сверхсложного, но и скорость достойная — в среднем меньше 0.001 сек. на генерацию странички и до 0.15 Мб памяти. Проекты построены на связке PHP + MySQL. Кстати, таким образом, второй из них, спокойно держит более 400тыс. хитов в сутки, со всплесками до 1600 хитов за минуту в пиках и почти 500 хостами онлайн. На VPS за $30/мес. А подключи к нему те три библиотеки, тогда уже не обойтись без выделенного сервера, и не самой слабой конфигурации. А ведь дело нередко доходит до применения с десятка готовых библиотек.
С другой стороны, безусловно, если вы разрабатываете небольшой сайт — для фирмы, или личную страничку, заботиться об оптимизации, и, таким образом, отказываться от применения готовых библиотек тут смысла нет. Время дороже. Если посещаемость вашего сайта не более 1000 посетителей в сутки, не стоит тратить время на идеальный и быстрый код. Пользуйтесь готовыми библиотеками. Вам хватит ресурсов любого хорошего виртуального хостинга. Если у вас посещаемость достигает 2-3 тыс. посетителей в сутки, уже есть смысл задуматься об оптимизации кода. Но все же следует хорошо подумать над тем, стоит ли вам на данном этапе отказываться от готовых библиотек и убивать время на переработку кода (либо же время и деньги на программиста, который это сделает). Зачастую проще просто купить дополнительных ресурсов, или перейти на VPS, оплачивая по $10-50 в месяц.
С другой стороны, следует учитывать сложность перехода на решения без применения готовых библиотек. Тот же движок новостного сайта я написал едва ли не за один день. Ведь кроме всего прочего, «тяжелые» скрипты не только требуют более мощного хостинга, но и замедляют открытие страничек сайта в браузере, особенно если страничка формируется в течение нескольких секунд. Если вам не очень накладно отказаться от применения готовых библиотек — я бы советовал делать это в любом случае.
Подводя итоги, еще раз подчеркну — вы можете спокойно применять библиотеки, наращивая мощность серверов, но не следует забывать, что это первая причина медленной работы ваших скриптов, и кроме высокой нагрузки на «железо», они являются причиной многих задержек загрузки страничек сайта.
2) Игнорирование Zend Optimizer, eAccelerator
Эти замечательные модули главным образом занимаются оптимизацией и динамическим кэшированием откомпилированного PHP кода (байт — кода ). Часто позволяют поднять производительность чуть ли не в десятки раз. Их применение имеет смысл в первую очередь на достаточно больших и высокопосещаемых проектах, хоть вы можете оптимизировать и любые другие сайты на PHP — это не потребует от вас по сути никаких дополнительных манипуляций. О применении данных модулей мы еще поговорим, в следующий раз, это достаточно объемная тема. Пока что вам достаточно запомнить этот пункт.
3) «Кривое» применение баз данных
По сути это отдельная тема. Вам следует помнить, что каждое подключение к БД, каждый запрос, каждая лишняя таблица в запросе и т.д. — все это создает ощутимую нагрузку. Но все же, логика самой БД, а не интерфейса работы с ней, несет наибольшую нагрузку. Мне недавно приходилось оптимизировать один очень популярный модуль для одного из самых популярных «движков» форума. Как мне сразу удалось выяснить — тот самый модуль и был главной причиной существенных тормозов. Добавив одну небольшую таблицу и два новых SQL запроса в PHP код, производительность форума была повышена на 60-80% (в зависимости от странички), потребление памяти снизилось на 5-7%! И это все практически на ровном месте. Как видите — это тот случай, когда добавление «лишней» таблицы и «лишних» запросов существенно увеличивает производительность. Я пошел не экстенсивным, а интенсивным путем, улучшив логику. И получив поистине замечательный результат.
На тему оптимизации БД мы поговорим в ближайшем будущем. Сейчас затрону лишь аспект, связанный с интерфейсом работы, как на PHP, так, впрочем, и на любом другом языке программирования.
Итак, прежде всего, всегда используйте файлы вместо БД, если в этом есть смысл. Когда в этом есть смыл? Предположим, вы пишите движок сайта новостей. Новость добавляется туда раз и навсегда. Она не подвержена последующим изменениям, она большая и цельная. Намного проще и эффективней поместить ее в отдельный файл, а не в БД. А вот рецензию к новости — уже лучше в БД. Ведь на определенных страничках вам явно придется выводить список последних рецензий по теме, или список случайных рецензий. Если писать каждую рецензию в отдельный файл — то при выводе, скажем, 50 рецензий на страничке, нам придется подключать к работе столько же соответствующих файлов рецензий. Писать все рецензии в один и тот же файл тоже не очень хорошо: при их большом количестве файл будет очень большим, и только разрастаться со временем, производительность же, соответственно — снижаться. Да и это попросту может быть достаточно неудобным и небезопасным делом — работа с такими файлами. Другое дело «закидать» наши небольшие рецензии в БД и «выдернуть» нужные одним несложным запросом. То же самое относится к любым часто редактируемым данным. Например, писать счетчик просмотров новостей на файлах — большая глупость. Только БД.
Что касается соединения с БД, его стоит закрывать как только в нем отпадает потребность. Однако, не стоит этого делать, если в работе данного скрипта оно еще пригодится.
Следите за содержимым переменных, которым присваиваются результаты выполнения запросов. Есть смысл использовать unset в ситуациях, когда серьезные объемы данных более не нужны.
4) Отсутствие кэширования
В целом ряде случаев кэширование просто незаменимо. Рассмотрим простой пример. Чуть выше, когда речь шла о БД, я приводил пример со списком рецензий. Предположим, мы заходим на некую страничку, где отображается список из 50 рецензий к последним новостям. Как правило, всех их можно выбрать из БД одним несложным запросом. Но с другой стороны, мы можем заранее создать некий файл, который будет содержать все эти 50 рецензий в готовом виде. Нам не нужно будет выбирать их из БД, форматировать согласно нашему шаблону и вставлять в нужное место в страничке. Мы просто сразу подключаем все это из заранее сформированного файла.
Суть кэширования сводится к созданию кэша из наиболее часто используемых и наиболее редко изменяемых данных. К примеру, как часто вам придется обновлять кэш ваших 50 рецензий? Ясно, что каждый раз, когда будут добавляться новые новости — чтоб наш кэш отображал актуальную информацию. А как часто будут добавляться новые новости? Предположим, примерно каждые 15 минут, т.е. до 100 раз за сутки. А какая посещаемость у этого сайта, как часто просматривают эти рецензии? На проекте, «движок» которого я разрабатывал, порядка 70 тыс. раз за сутки. Таким образом, вместо того, чтобы выполнять выборку из базы, форматирование и вставку этих рецензий по 70 тыс. раз на сутки, она выполняется обычно не более 100 раз, остальное — лишь простые инклуды полностью готовых данных.
Вы должны по возможности создавать окончательно завершенные данные для кэширования, которые достаточно просто подключить к страничке в процессе выполнения запроса, без надобности парсинга, дообработки, шаблонизирования и т.д.
Не забывайте о том, что кэш не обязательно хранить только в файлах и в нем не обязательно можно хранить только части нашей будущей HTML — странички. А особенно если он подвержен частым, систематическим обновлениям. Например, список данных о пользователях, находящихся онлайн, гораздо разумней держать в БД, в таблице типа Memory.
5) Буфер, сжатие, фронтенд http-сервер
Все очень просто. В процессе выполнения все данные, которые выводятся пользователю, тут же ему и отправляются. Грубо говоря, пока данные не будут забраны, продолжение выполнения кода не выполняется. Так что если в процессе работы ваш скрипт отправляет готовый HTML — код через функцию echo, например, или любым другим методом, то крипт передает данные «по кусочкам», каждый раз «подвисая». Намного грамотней выводить данные в буфер, примерно так:
php//инициализируем буферизациюob_start (); //выполнение кода скрипта
//... //завершаем буферизацию, извлекаем данные
$html = ob_get_contents ();
ob_end_clean ();
exit ( $html ); ?>
Включение динамического сжатия готовых HTML — страниц (
ob_start(`ob_gzhandler`);) может сжать их в среднем на 20-60%, увеличивая скорость загрузки и снижая количество «висящих» процессов. У вас ограничение по трафику на хостинге? Тогда динамическое сжатие страниц принесет двойную выгоду.
Конечно, следует учитывать, что буферизация несколько повышает потребление памяти, а сжатие — нагрузку на процессор. Но эти жертвы зачастую с лихвой окупаются приростом скорости. Причем не только скоростью создания, но и скоростью загрузки странички.
В завершение, фронтенд http-сервер может вывести производительность ваших PHP скриптов на новый уровень. Дело в том, что даже с кэшированием, процессы, связанные с запросом пользователя, будут «висеть» до того, пока пользователь не примет все данные (либо пока не выйдет лимит отведенного на это времени). Суть фронтенд сервера в том, чтобы сразу же принимать данные, позволяя сразу выгружать отработавшие процессы. Он является неким связующим звеном между пользователем и достаточно «тяжелым» бэкенд сервером — где выполняются ваши PHP скрипты. Но благодаря своей «легкости», фронтенд сервер существенно снижает потребляемые ресурсы. Опять-таки, это очень обширная тема и мы будем рассматривать ее более детально, в ближайшем будущем.
6) Тотальный инклуд
Предположим, вы создали свой «движок» на PHP, соблюдали все предыдущие советы. В нем практически неизбежно будет множество различный инклудов: файлов конфигурации, функций, языков и т.д. Суть сводится к тому, что даже обычный инклуд того же файла с функциями будет требовать немало времени и памяти, даже если кроме функций в инклуде нет никакого исполняемого кода, и не одна из функций не вызывается.
Но ведь функции бывают самые разнообразные и специфические. Так что помещать весь список функций в один файл, и каждый раз подключать его — не лучший выход. Например, на сайте есть регистрация пользователей: для этого у вас может быть целый ряд специальных функций, которые используются только при регистрации. Так зачем выносить их в общий инклуд функций, который будет подключаться при каждом обращении к страничкам сайта?
Не пренебрегайте оптимизацией инклудов. Выносите то, что применяется не повсеместно в отдельные, специализированные инклуды. Еще один пример для закрепления. Мой любимый движок новостного сайта. Функции добавления новостей, комментариев, их контроля и пре-парсинга занимает около 1/3 кода общего количества функций. Но как часто они необходимы? В 1 из 100 запросах? Или в 1 из 200? Или еще реже? Так зачем же их каждый раз грузить? Это действительно может существенно снизить производительность ваших решений.
7) Лишняя функциолизация и ООП-тимизм
Функции необходимо применять только тогда, когда это действительно имеет смысл. Давайте вспомним базовую цель функций. Это не что иное, как вынос
часто используемых в пределах одного цикла работы программычастей кода в отдельную, общую часть. В принципе, выносить код в «отдельную часть» имеет смысл и тогда, когда он выполняется по некому, относительно маловероятному событию. К примеру, прикрепление фото к посту на форуме. Вынос обработчика загрузки и обработки картинки в «отдельную часть» позитивно отразится на производительности, даже если он заключен в условие (факт загрузки картинки). При этом, если данная «отдельная часть» нам понадобится лишь один раз, лучше выполнить ее просто как код (инклуд), а не как функцию. Функции всегда требуют некоторых дополнительных ресурсов. То же самое касается и ООП-программирования в PHP. ООП-код потребляет несколько больше ресурсов, поэтому если вам не принципиально ООП-форматирование кода, лучше отказаться от него. Я говорю именно о ООП-форматировании, поскольку ООП-подход в PHP имеет мало общего с самим понятием ООП-программирования. Как и PHP с классическим пониманием языков программирования и их задач — о чем я писал в начале.
Вот вы и ознакомились с 7 основными принципами производительного кода на PHP. Это только — только самое начало. Впереди у нас еще много интересного, более конкретного материала по данной теме.
Читайте также...